
Speech Emotion Recognition (SER)
AI
Speech Emotion Recognizer
This is my first real practical journey on creating an app to recognize a limited set of human emotions from a recorded voice. The model behind the app has been trained to recognize six emotions, apart from neutral: angry, disgust, fear, happy, sad and surprise. These sort of apps belong to the category of speech emotion recognition field, or SER.
Why
A bit after ChatGPT came along an became a boom, around March 2023, I saw myself creating a voice assistant to have meaningful conversations with. Having experienced the dialogue limitations of Alexa, Siri and the likes, I intended to direct the microphone audio stream to the OpenAI API, to get a meaningful answer that could result in having an interesting dialogue. Thinking of my dad, my purpose was to create such a voice companion app to help elders feel less lonely. Soon I realized, that for the companion app to be effective it needed to be aware of the emotion the speaker had when uttering. Thus if the app senses a “blue” or sad mode, it could adapt its answer, compared to when the app senses a happy mode. This is why I dwelved into understanding how to train a model for sensing basic emotions, that are relevant when two people are having a conversation.
How it was built
The first model I used, was not trained by me, it was trained by Neurolex back in 2018, but it served as a good starter. The model “model_v5.h5” was trained using features extracted from public audio dataset with utterances recorded by trained actors reading a script and acting one of the above mentioned emotions. The features were extracted with librosa library (excellent one btw) using the mfcc feature extraction. The first 13 features of the Mel-frequency Cepstral Coefficients were used to create the dataset for training and testing the model. These features work pretty much as a band-pass filter for the audio, that mimics how the human hearing works, where the perceived loudness changes according to frequency. See this Jonathan Hui article for more reading. With the model at hand, I used Huggingfaces and Gradio library to create a visual interface for the app.
Built with Python, both model and visual interface.
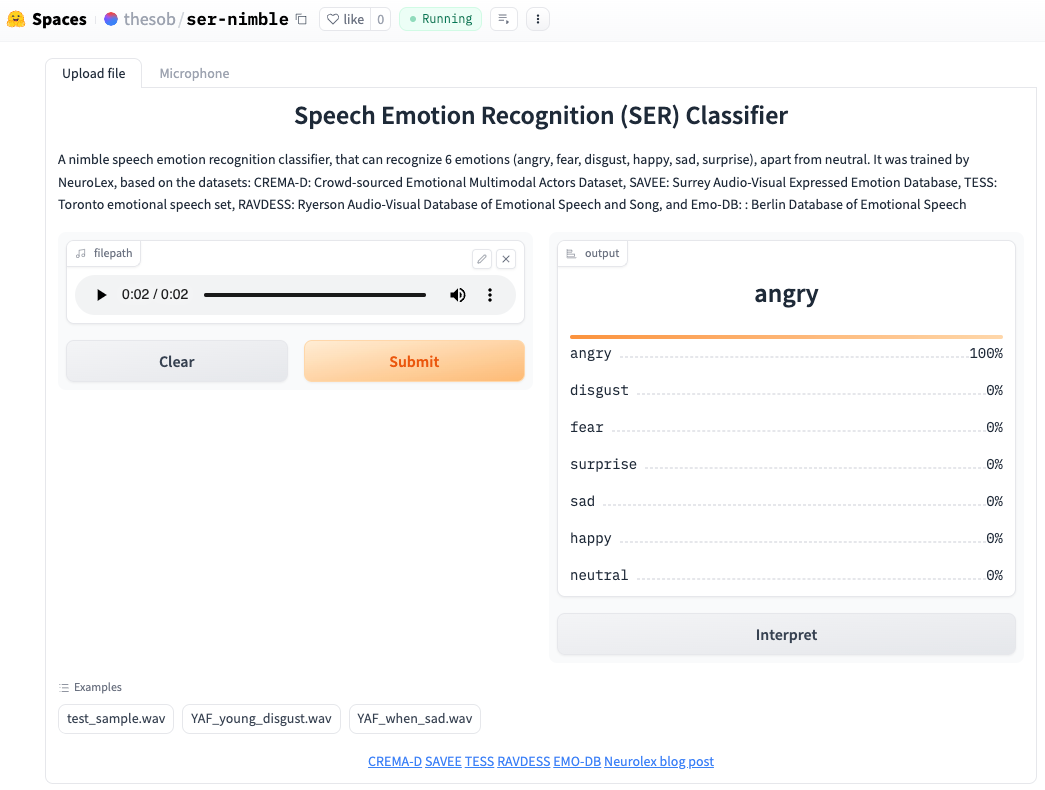
Deployed on Huggingface Spaces spaces a SER-nimble. Used Gradio library to create the visual interface connected to the model. Code repositoy on Github
Decisions made
- Made the UI very simple for usability. The idea was to have a platform where I could easily validate live the accuracy of the trained model. i.e. using an audio that was not part of the training or test data set.
Packages used
- Keras sequential model Model architecture is a multi-layer sequential model using Keras library components for convolution, activation and max pooling, and contains over 450K parameters.
It’s structure is as follows:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv1d_12 (Conv1D) | (None, 217, 32) | 192 |
| activation_17 (Activation) | (None, 217, 32) | 0 |
| max_pooling1d_11 (MaxPooling1D) | (None, 108, 32) | 0 |
| conv1d_13 (Conv1D) | (None, 108, 64) | 10304 |
| activation_18 (Activation) | (None, 108, 64) | 0 |
| max_pooling1d_12 (MaxPooling1D) | (None, 54, 64) | 0 |
| dropout_7 (Dropout) | (None, 54, 64) | 0 |
| flatten_4 (Flatten) | (None, 3456) | 0 |
| dense_7 (Dense) | (None, 128) | 442496 |
| activation_19 (Activation) | (None, 128) | 0 |
| dropout_8 (Dropout) | (None, 128) | 0 |
| dense_8 (Dense) | (None, 7) | 903 |
| activation_20 (Activation) | (None, 7) | 0 |
Total params: 453895 (1.73 MB) Trainable params: 453895 (1.73 MB) Non-trainable params: 0 (0.00 Byte)
-
Gradio Used TabbedInterface, to combine to interfaces, one for file upload and one for microphone.
-
Librosa Used to extract MFCC features from training data set, and then to create the input to the model to produce the prediction of the label (emotion). Only the first 13 features were used.
Lessons learned
Gradio is an excellent library to both create visual environments for machine learning models, and expose apis for other apps to consume.
The Nuerolex respository hasn’t been maintained since many years ago, and the model shared is not reproducing the accuracy sustained, 86 %. (It may have to do with an improper use of the model)
What to improve or make different next time
- Investigate whether the predict call in the Gradio app is calling predict incorrectly:
- Since the model was created in 2019, it has an old pickle format version.
- The demo code in link refers to an output of size 216, when the model clearly states 217
- Keras version with which the model was created in 2019 contains a method predict_classes that does not exist in current version (2023), so I used predict_batch instead Thus, as can be seen in this predict function below,
def predict(filepath):
X, sample_rate = librosa.load(
filepath,
res_type='kaiser_fast',
#duration=2.5,
sr=22050*2,
offset=0.5
)
#convert array into numpy array
sample_rate = np.array(sample_rate)
#calculate MFCC mean
mfccs = np.mean(
librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=13),
axis=0)
#store in temporary variable
test_sample_features = mfccs
#pad and reshape the MFCC feature extraction for input into the model
test_sample_features = np.pad(
test_sample_features,
(0, 217-test_sample_features.shape[0]),
'constant'
)
test_sample_features = test_sample_features.reshape(1, 217, 1)
probs = model.predict(test_sample_features)
#return str(probs) + ' dtype:' + str(probs.dtype) + ' size:' + str(probs.size) + ' shape:' + str(probs.shape)
return {labels[i]: float(probs[0,i]) for i in range(len(labels))}
- Retrain a CNN model, e.g. ResNet50, for transfer learning on spectrograms for the labeled audio data set. It is very similar to what the MFCC does, but relies more on graphical analysis.